
EMOJI表情插入MYSQL数据库异常记录报错以及处理方式
这个问题是由于数据库中字符集编码一般我们用utf8,utf8存储一般为2到3字节,但是emoji是四个字节导致插入错误,所以我们要更改字符集为utf8mb4
mysql的版本必须为5.5.3以上
1.先登录MYSQL,查看当前数据库的编码格式
1 | show variables like 'char%'; |
| Variable_name | Value |
|---|---|
| character_set_client | utf8mb3 |
| character_set_connection | utf8mb3 |
| character_set_database | utf8mb3 |
| character_set_filesystem | binary |
| character_set_results | utf8mb3 |
| character_set_server | utf8mb3 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql-8.0/charsets/ |
我们看到并不是utf8mb4
2.在查看排序规则
1 | show variables like 'collation_%' |
| Variable_name | Value |
|---|---|
| collation_connection | utf8_general_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
也不是,这时候开始修改
3.修改MYSQL配置文件 MY.CNF
找不到可以用以下代码,文件一般在etc/mysql/my.cnf
1 | mysql --help | grep my.cnf |
加入
1 | [mysqld] |
4.重启MYSQL
1 | sudo service mysql restart |
5.回到第一步看下字符集是否更改否则,再MYSQL里面运行以下设置代码
1 | set character_set_client = utf8mb4; |
6.再次查看
1 | show variables like 'char%'; |
| Variable_name | Value |
|---|---|
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql-8.0/charsets/ |
| Variable_name | Value |
|---|---|
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_0900_ai_ci |
修改表及字段字符集
同样的,对于已经创建的表,修改全局及数据库的字符集并不会影响原表及字段的字符集。
原有的 utf8 表可以采用如下方法修改:
1 | #修改数据库字符集 |
查看字符集
1、查看数据库支持的字符集:
select * from information_schema.character_sets;
2、查看数据库支持的检验规则:
select * from information_schema.collations;
3、查看表字符集及检验规则:
show create table tb_name
select * from information_schema.tables where table_name=tb_name
MySQL几种编码格式的区别(utf8、utf8mb4、utf8mb4_general_ci、utf8mb4_unicode_ci 、utf8mb4_0900_ai_ci)
存储字符集 utf8 和 utf8mb4
utf8 是 Mysql 中的一种字符集,只支持最长三个字节的 UTF-8 字符,也就是 Unicode 中的基本多文本平面。
要在 Mysql 中保存 4 字节长度的 UTF-8 字符,需要使用 utf8mb4 字符集,但只有 5.5.3 版本以后的才支持。我觉得,为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 Mysql 官方建议,使用 VARCHAR 替代 CHAR。
如果数据库默认字符集不是 utf8mb4,那么可以在创建数据库时指定字符集:
1 | CREATE DATABASE mydb CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; |
查看编码格式
1 | show variables like "%char%"; |
MySQL 配置文件中字符集相关变量
- character_set_client:客户端请求数据的字符集
- character_set_connection:从客户端接收到数据,然后传输的字符集
- character_set_database:默认数据库的字符集,无论默认数据库如何改变,都是这个字符集;如果没有默认数据库,那就使用 character_set_server 指定的字符集,这个变量建议由系统自己管理,不要人为定义。
- character_set_filesystem:把操作系统上的文件名转化成此字符集,即把 character_set_client 转换 character_set_filesystem, 默认 binary 是不做任何转换的
- character_set_results:结果集的字符集
- character_set_server:数据库服务器的默认字符集
- character_set_system:存储系统元数据的字符集,总是 utf8,不需要设置
排序字符集
utf8mb4_unicode_ci 和 utf8mb4_general_ci
1、准确性
utf8mb4_unicode_ci 是基于标准的 Unicode 来排序和比较,能够在各种语言之间精确排序
utf8mb4_general_ci 没有实现 Unicode 排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。
但是绝大多数情况下,这些特殊字符的顺序并不需要那么精确。
2、性能
utf8mb4_general_ci 在比较和排序的时候更快
utf8mb4_unicode_ci 在特殊情况下,Unicode 排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
但是在绝大多数情况下,不会发生此类复杂比较。相比选择哪一种 collation,使用者更应该关心字符集与排序规则在 db 里需要统一。
utf8mb4_0900_ai_ci
推荐用 utf8mb4_unicode_ci,但是用 utf8mb4_general_ci 也没啥问题。
MySQL 8.0 默认的是 utf8mb4_0900_ai_ci,属于 utf8mb4_unicode_ci 中的一种,具体含义如下:
- uft8mb4 表示用 UTF-8 编码方案,每个字符最多占 4 个字节。
- 0900 指的是 Unicode 校对算法版本。(Unicode 归类算法是用于比较符合 Unicode 标准要求的两个 Unicode 字符串的方法)。
- ai 指的是口音不敏感。也就是说,排序时 e,è,é,ê 和 ë 之间没有区别。
- ci 表示不区分大小写。也就是说,排序时 p 和 P 之间没有区别。
utf8mb4 已成为默认字符集,在 MySQL 8.0.1 及更高版本中将 utf8mb4_0900_ai_ci 作为默认排序规则。以前,utf8mb4_general_ci 是默认排序规则。由于 utf8mb4_0900_ai_ci 排序规则现在是默认排序规则,因此默认情况下新表格可以存储基本多语言平面之外的字符。现在可以默认存储表情符号。如果需要重音灵敏度和区分大小写,则可以使用 utf8mb4_0900_as_cs 代替。
UTF-8 与 UTF-8MB4 的区别
UTF-8 (Unicode)
我们先谈谈UTF-8,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。现代操作系统和大多数编程语言都直接支持Unicode。
所以在UTF-8编码中,一个英文字符占用一个字节的存储空间,一个中文(含繁体)占用三个字节的存储空间。
目前基本上可见字符集都只需要三个字节,包含了所有字符,但是目前问题出在了unicode6系列编码上,它们需要4个字节,这部分就是有名的emoji。所以,你只要不是特种编码还是unicode,且不存emoji,保证不出问题。
另外在此处,我有一点需要补充的是:
MySQL数据库的 “utf8”并不是真正概念里的 UTF-8,原因上面是一点,还有一点是MySQL中的“utf8”编码只支持最大3字节每字符。真正的大家正在使用的UTF-8编码是应该能支持4字节每个字符。
但其实MYSQL的开发者,并没有修饰这个bug,而是推出了新的字符集,就是UTF-8MB4字符编码。
UTF-8MB4
UTF8MB4:MySQL在5.5.3之后增加了utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。因此可以用来存储emoji表情。
从8.0后,MySQL也将会在某个版本中开始使用UTF-8MB4作为默认的字符编码。
所以简单说即是:UTF-8MB4才是MySQL中真正的UTF-8编码。
那么如何让MySQL存储Emoji表情勒。
如何让MySQL存储Emoji表情
我们在创建数据库的时候,就需要选定utf-8mb4字符集,而不是utf-8。
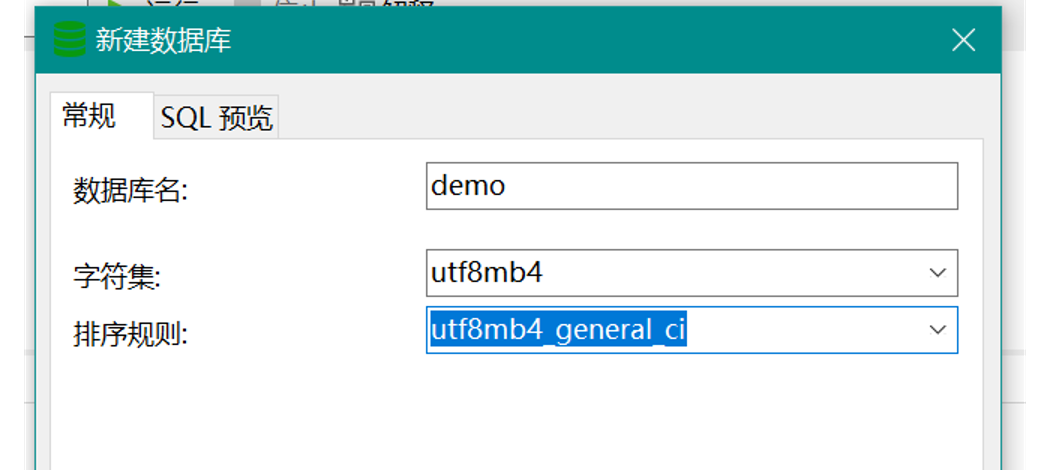
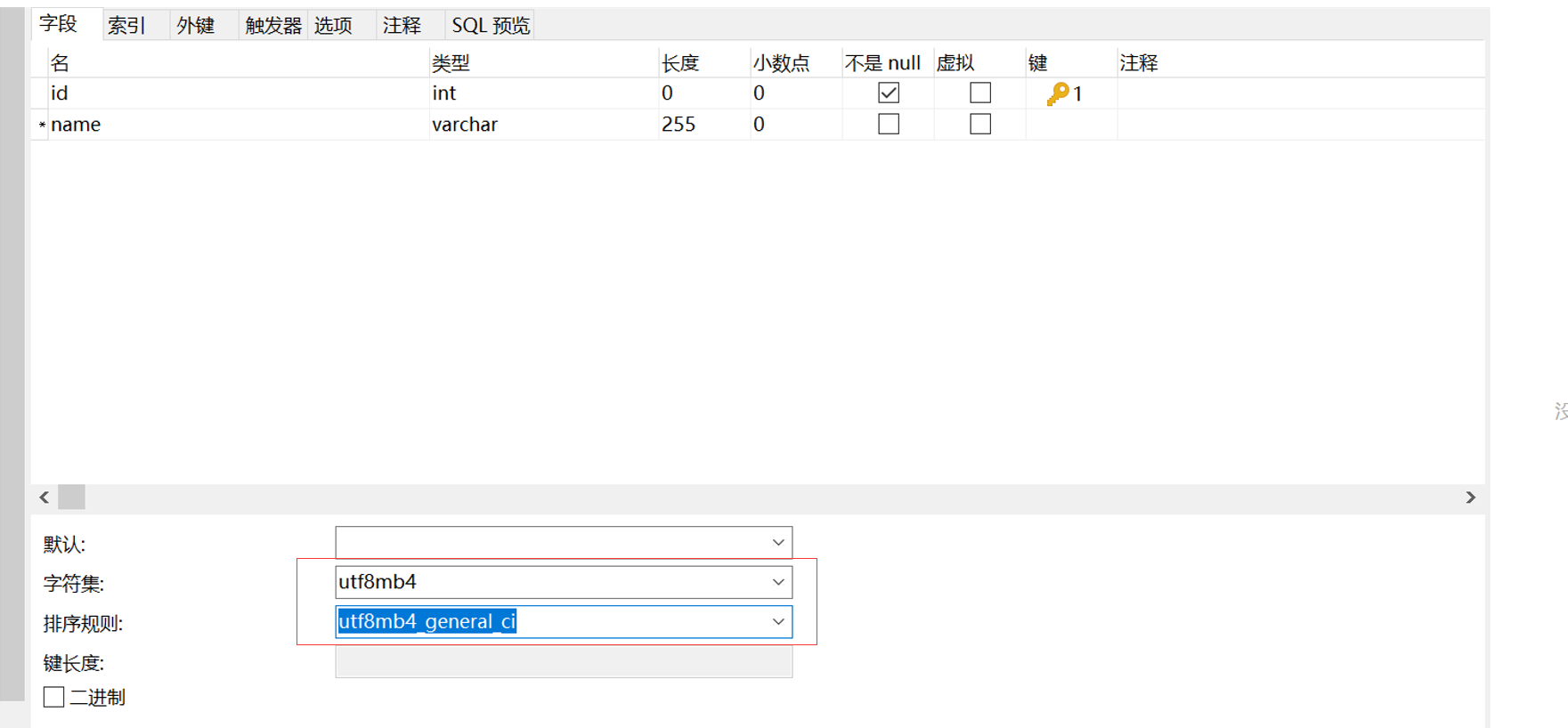
我们在设置字段字符集的时候,也需要设置为utf-8mb4字符集。
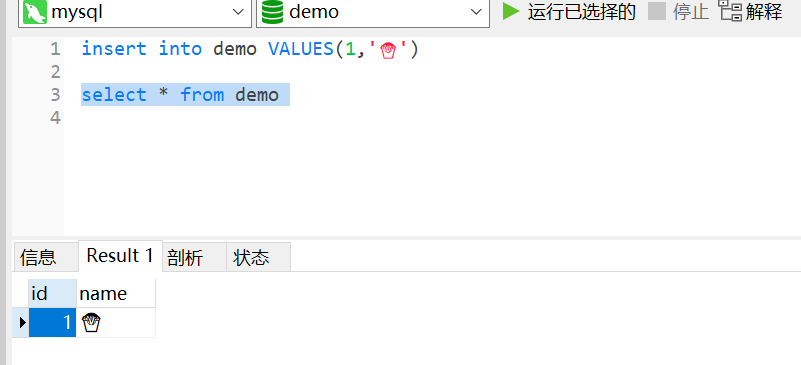
这样我在Navicat 中测试是可以的。
但是,我之前在网上查询相关资料的时候,说是需要修改一下my.ini配置文件,
在[mysqld]下面添加:character_set_server=utf8mb4,保存,重启mysql,应该就可以解决了。
注意:下次再有人问起设置什么样的编码,记得直接推荐设置utf-8mb4哦,这个才是MySQL真正的UTF-8编码哦。
一些建议
看起来修改方法挺简单,不过对于生产环境还是要格外小心。特别是修改字段字符集时,会加锁,阻止写操作,对于大表执行下来也是很慢的,可能对线上业务造成影响。
如果你的数据库比较小,用以上方法应该问题不大。对于线上环境,若要修改字符集,一定要做好评估,最好可以在业务低峰期停机修改,修改前一定要先备份。若无停机时间,可以考虑先在备库修改,然后再主备切换,不过这样做会更麻烦。
有条件的话也可以再准备一个空实例,先导入表结构,改成 utf8mb4 字符集后再导入数据。这也是一种方法,不过也可能需要停机切换。